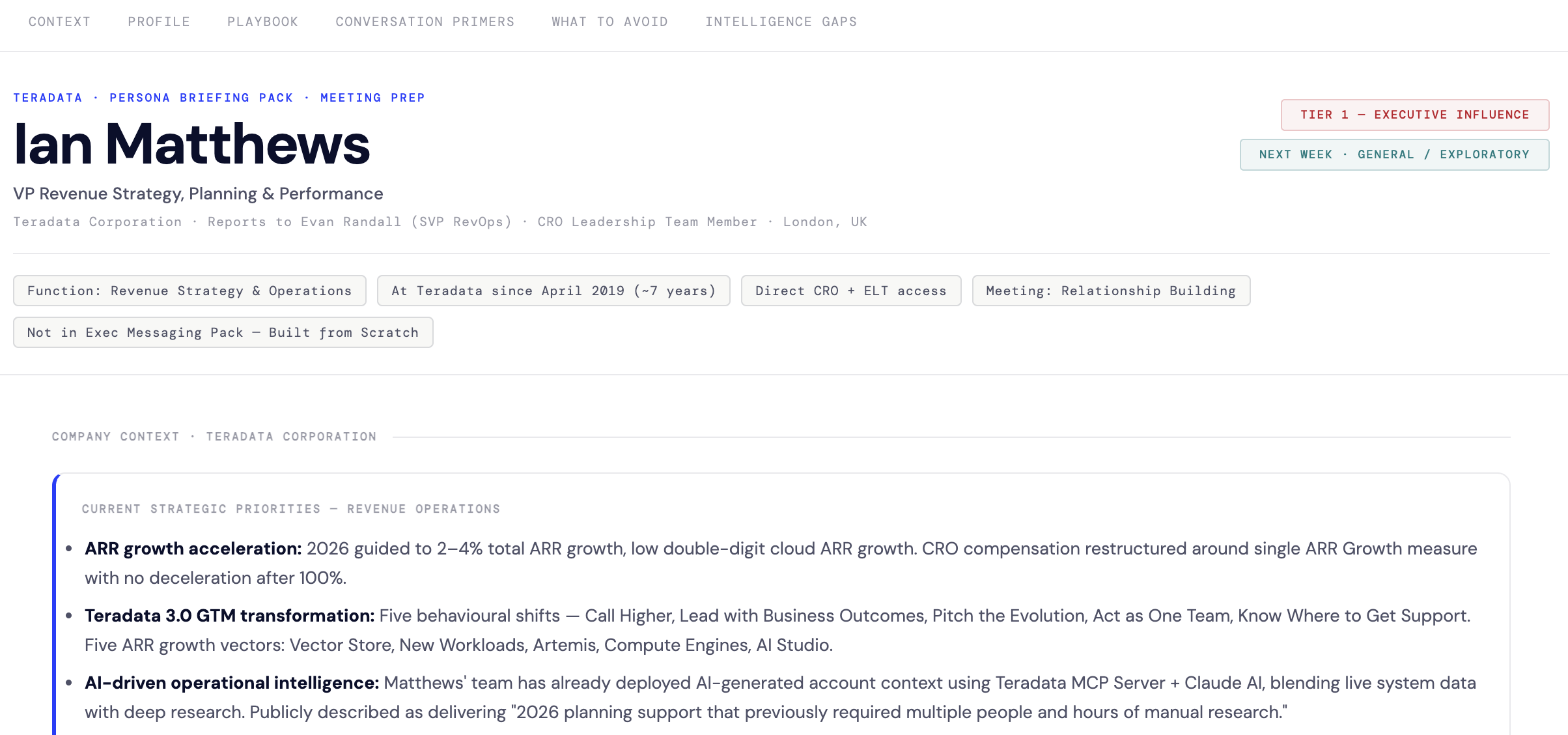
The RevOps roles that survive AI aren’t the ones people are protecting
Let me start with a number that’s uncomfortable to say out loud: roughly half of current revenue operations roles will look fundamentally different within the next 18 months. Not automated away entirely. That’s the wrong frame for it. Hollowed out is closer. The tasks those roles were hired to perform will stop requiring dedicated human effort. The people doing them will either evolve or become expensive.
The instinct when facing that reality is to protect the skills you’ve built rather than ask honestly whether they’ll still be worth protecting. They won’t all be. The question is which ones will.
The skills that disappear first
For most of my career, I took genuine pride in being able to do things with complex data that most people couldn’t. Getting Excel to produce analysis that took real craft. Building models that made a difficult commercial story legible to a leadership team. Those skills created real value. They also required real time and real expertise.
They’re becoming obsolete. Any reasonably capable operator working with AI tooling can produce in an afternoon what used to take a senior analyst a week. The outputs are still valuable. The specialist to produce them is not. The value was never in the mechanics of the work; it was in knowing what questions to ask and what to do with the answers. AI handles the mechanics now.
The roles built primarily around high-skilled data manipulation, including building dashboards, maintaining reporting pipelines, and running standard analysis on CRM output, are going first. What replaces them is something smaller, faster, and more automated. Some organisations have already made these hires redundant without quite realising that’s what they’ve done.
The GTM Engineering counterargument
There’s a counter-narrative worth addressing directly, because it’s gaining traction in exactly the communities that should know better.
GTM Engineering, the discipline of building signal-based workflows, automating enrichment pipelines, and creating the technical infrastructure that makes AI agents function, is real and it’s useful. Some organisations genuinely need people who can build rather than just configure. The problem is the way it’s being positioned: as the new RevOps, the survival role, the thing that replaces everything that’s being automated away.
It isn’t. It’s a narrow, specialised function that solves a specific technical problem. And it’s already being automated.
Clay is the clearest example. Building enrichment workflows in Clay initially required people who understood the tooling well enough to construct and maintain them. Clay then shipped AI that automates significant portions of what those people were doing. The GTM Engineer configuring multi-step enrichment sequences is watching the same pattern play out that the dashboard analyst watched two years ago: the technical execution layer commoditises, leaving the judgment layer exposed.
The organisations treating GTM Engineering as a strategic destination are building on a platform that will shift beneath them. The ones treating it as a useful current-state capability, while building the knowledge infrastructure that will outlast it, are making the right long-term bet.
The problem with how most organisations are responding
Most organisations are treating AI adoption as a tool selection exercise. Find a promising capability, put it in place, see what happens. That’s fine for experimentation. It’s not a strategy.
The deeper problem is that AI doesn’t improve a broken process. It scales it. If you can’t say what good prospect engagement actually looks like, if you don’t know what a relevant signal is or what your value proposition means to a specific account in a specific situation, then automating your outreach doesn’t help. It makes the problem faster and larger. I’ve seen organisations push tens of thousands of AI-generated messages into the market on the back of a process that didn’t work at a hundred messages a week. The efficiency gain is genuine in terms of what just a few people can do. The reputational damage is too, and that’s the part that’s harder to fix.

This is the core failure pattern: deploying AI before the underlying operating system deserves to have AI deployed on it. Strategy has to exist before data foundations are designed. Data foundations have to exist before data products can be built. Data products have to exist before AI can use them effectively. Getting that sequence backwards doesn’t only produce poor results. It produces poor results confidently, at speed, with the ability to scale exponentially which is harder to stop than the original problem.
What data products actually are, and why they’re the bridge
The term “data product” has enough consulting baggage that it’s worth being specific. A data product is a structured, governed, repeatable approach to turning raw data into something consumable. It has defined inputs and outputs, an owner, clear linkage, and documentation. It’s designed to be used by AI, by applications, by people. Not just stored.
The Excel report that lands in your inbox every Monday morning is a data product. It’s processed in a repeatable way. You know what it means. You can act on it. What matters is that it transforms data into knowledge, and that knowledge can be referenced, built upon, and connected to other systems.
At scale, data products become the interface between your data foundation and everything that consumes it. Feed raw data to an AI and it constructs context from scratch, every time, without the business understanding you’ve spent years developing. Feed it a well-structured data product and it starts with that context already in place. The output quality gap is substantial and the speed difference more so.
This is where RevOps will create disproportionate value going forward: not in producing outputs, but in building the structures that allow AI and teams to produce outputs continuously, reliably, and at a quality that a one-off analysis never achieves.
The IP problem nobody is talking about loudly enough
There’s a version of AI adoption that feels sophisticated but creates a structural risk most organisations won’t notice until they’re already exposed to it.
When you adopt an overarching platform, one that manages your data, runs your analysis, and generates your insight, the analytical knowledge that platform produces stays inside that platform. The models it builds about your customers, your pipeline patterns, your account relationships: that’s your business’s intellectual property, and it lives in someone else’s system. Imagine how hard it will be at the moment you realise that you need to change provider or integrate other applications with that knowledge.
This isn’t theoretical. Enterprise legal teams are now routinely negotiating explicit data ownership clauses into AI platform contracts, confirming that all data, models, prompts, and fine-tuning outputs belong to the business and not the vendor. The commercial logic is clear enough: buying is faster than building. The risk sits right alongside it. The knowledge that makes your revenue engine distinctive, your understanding of which signals predict deals, which patterns precede churn, what your best accounts actually look like, lives in a system you don’t control and whose interests are not identical to yours.
The right architecture keeps your core data and the knowledge derived from it inside structures you own. Tools, platforms, and AI connect to that knowledge. They don’t contain it. The knowledge hub becomes the asset. Everything else connects to it rather than replacing it.
This also matters beyond the legal question. AI conversations are ephemeral. The context a team builds over weeks of working with a model, the account nuance, the commercial framing, the pattern recognition, evaporates between sessions unless it’s deliberately structured and stored. Organisations that build knowledge capture into their operating model are compounding. Organisations that don’t are starting from scratch every time.
What this looks like when it works
The most concrete example I can give is strategic account management as it’s been at the heart of every company i’ve worked with. Account planning in large enterprise businesses is one of those activities that everyone agrees is critical and nobody has enough time for properly. Understanding what’s happening at a key account, including internal consumption patterns, external signals, competitive activity, and stakeholder changes, used to require pulling data from multiple systems, supplementing it with manual research or domain expertise, and synthesising it into something an account team could actually use.
We measured the effort recently. Approximately 24,000 hours annually, just to prepare the insight that preceded account planning conversations. Teams are spending more time gathering data and interrogating the systems, than discussing how they could drive value for their customers. That volume meant account planning happened once a year, because maintaining that level of detail continuously would require more dedicated headcount than any organisation could justify.
By building the right data foundation, structuring it into consumable data products, and connecting those products to AI via an architecture that kept the outputs in systems the business controlled, the same insight became continuous: available for a much larger set of accounts, updated in real time, sourced from knowledge the business owns. Quarterly account insight briefings delivered automatically to account teams. On-demand support for competitive positioning, executive messaging, meeting preparation, and account analysis, all from a knowledge layer the organisation controls rather than a platform that does.
That’s not a multi-year transformation programme. The proof of concept moved into business production in weeks with a small team of AI specialists working with GTM domain experts. The difference was having the data foundation and the data products in place before the AI was connected. Without that foundation, the same investment produces sophisticated-looking noise.

What RevOps actually becomes
The technical execution skills that defined RevOps over the past decade will continue to exist, but as specialised consultancy and automated tooling rather than core team capability. The roles primarily hired to produce outputs will be replaced by systems that produce those outputs faster and more consistently. That includes, eventually, the newer technical roles that build those systems.
The roles that survive and compound in value are different in character. They build the data foundations that reflect real strategic choices. They design the data products that make those foundations consumable. They maintain the context stores and knowledge hubs that give AI and teams a shared base of business understanding. They know which questions are worth structuring the system to answer.
That’s a smaller team doing more consequential work. The commercial engine doesn’t get simpler. What changes is who manages its complexity, and what they use to do it.
The organisations that figure this out first will have a compounding advantage. The knowledge structures they build become more valuable every quarter as more context accumulates in systems they own. The ones that don’t will keep buying capabilities that plug into knowledge they don’t control, and will discover at some inconvenient moment that their competitive intelligence lives in someone else’s platform.
Revenue operations isn’t dying. The part worth protecting is just different from the part most people are currently protecting. I speak on AI in RevOps at industry events throughout the year; it’s the topic that generates the most questions.